
Yi (Joshua) Ren
Hey, I am a postdoc at Oxford Applied and Theoretical Machine Learning Group (OATML) led by Prof. Yarin Gal at the University of Oxford. I obtained my Ph.D. in 2025 with Prof. Danica J. Sutherland at the University of British Columbia (UBC). I also visited Prof. Aaron Courville's group at Mila, working on applying iterated learning in general representation learning problems. Before that, I was a master's student at the University of Edinburgh, working with Prof. Simon Kirby and Prof. Shay Cohen on iterated learning and compositional generalization. I also interned at Borealis AI and Cohere , working on time-series learning dynamics and LLMs’ post-training, respectively.
Email / Google Scholar / GitHub / Twitter / CV
Intro. of My Research (Previous)
I am exploring how to train models that generalize well systematically and why effective models naturally adhere to Occam's Razor.
This idea stems from a
talk
by Professor Simon Kirby, which discussed how the pressures of compressibility and expressivity drive human language to evolve in a more compositional direction.
We observe that not only humans but also neural networks tend to favor highly compositional mappings when trained on various tasks.
Such a simplicity bias may be progressively amplified if an intelligent agent continuously learns from the data and experiences of its predecessors,
which is a key concept in Bayesian-iterated learning (Bayesian-IL) in cognitive science.
Investigating this intriguing framework has inspired two lines of my previous research.
First, I worked on extending the iterated learning framework to more general deep learning systems, starting with an emergent communication setting
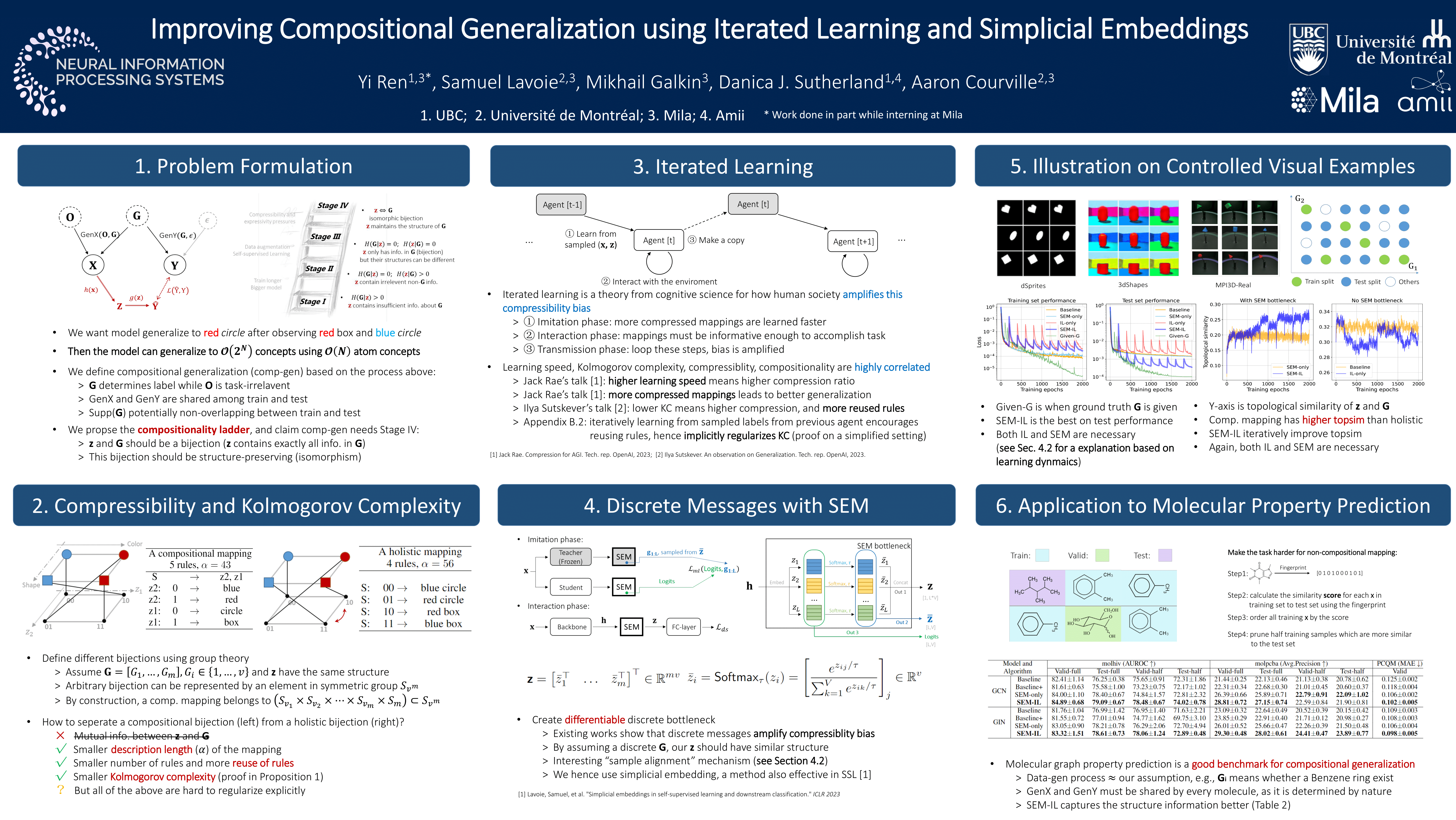
(a two-agent cooperative RL game, in Ren et al., ICLR 2020) and progressing to broader representation learning problems, including vision, language,
and even molecular graphs (in Ren et al., NeurIPS 2023).
The latter was achieved during my visit to Professor Aaron’s group at Mila.
We discovered that a bottleneck in the network structure plays a critical role in introducing implicit bias, which is further amplified through multi-generation self-play.
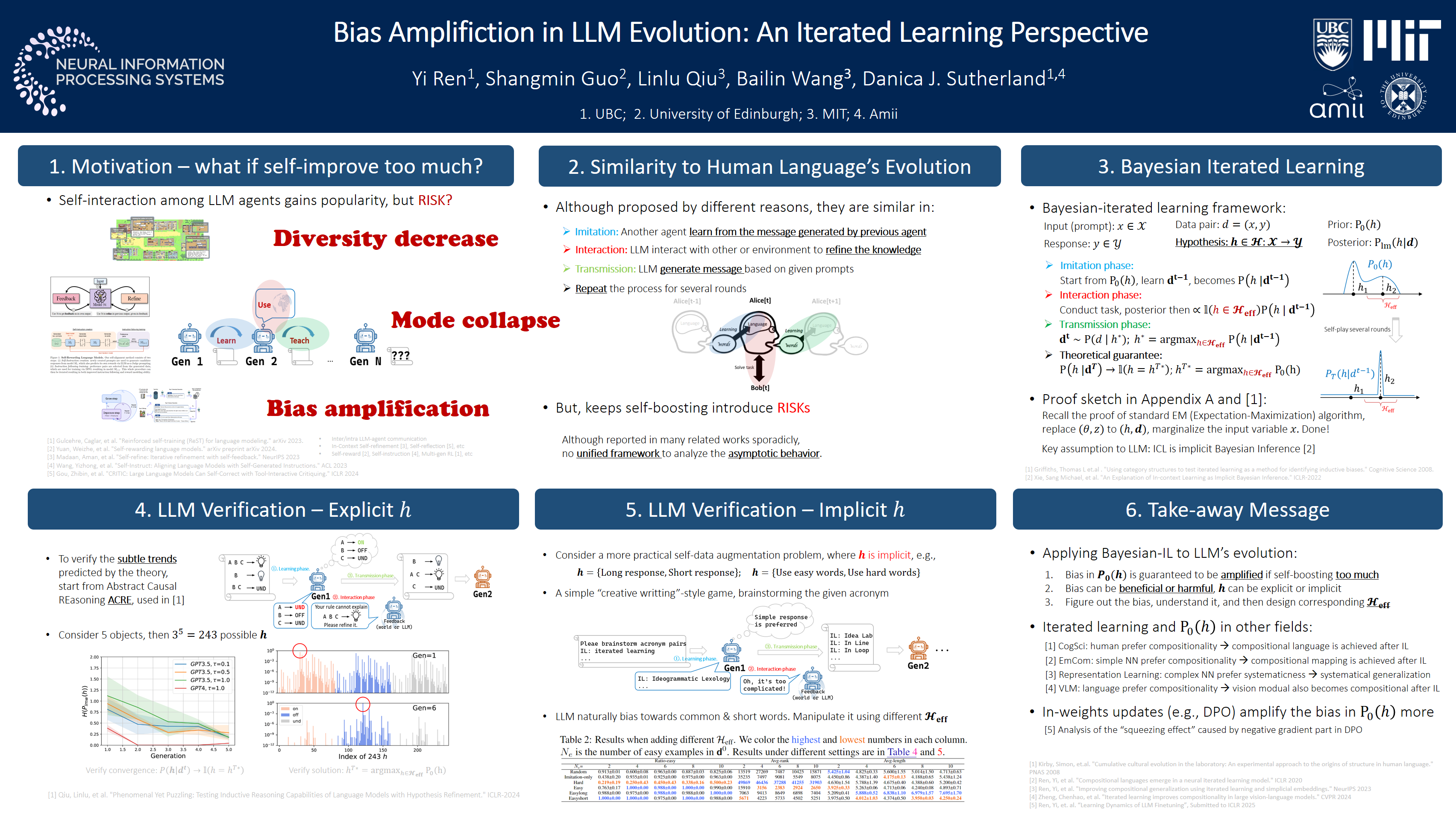
Additionally, our recent work demonstrates that Bayesian-IL partially explains the evolution of large language models (LLMs) in pervasive self-play (in Ren et al., NeurIPS 2024).
This not only sheds light on why specific phenomena, such as diversity reduction and hidden bias amplification, occur in many self-improvement methods but also offers insights into mitigation
-- namely, designing effective interaction phases to constrain unwanted biases.
Another line of work, which I am currently focusing on, explores the origins of the simplicity bias.
One theoretical tool we use is learning dynamics, which examines how a model’s prediction on one example changes when it learns from another.
This tool allows us to quantify simplicity bias through measurable properties such as learning speed or compression rate.
Since a model cannot learn all possible data at once, it acquires new knowledge sample by sample.
If learning from each example enables the model to make more accurate predictions on other samples, the training curve will decay rapidly,
indicating a higher compression ratio (as highlighted in this talk on Compression for AGI).
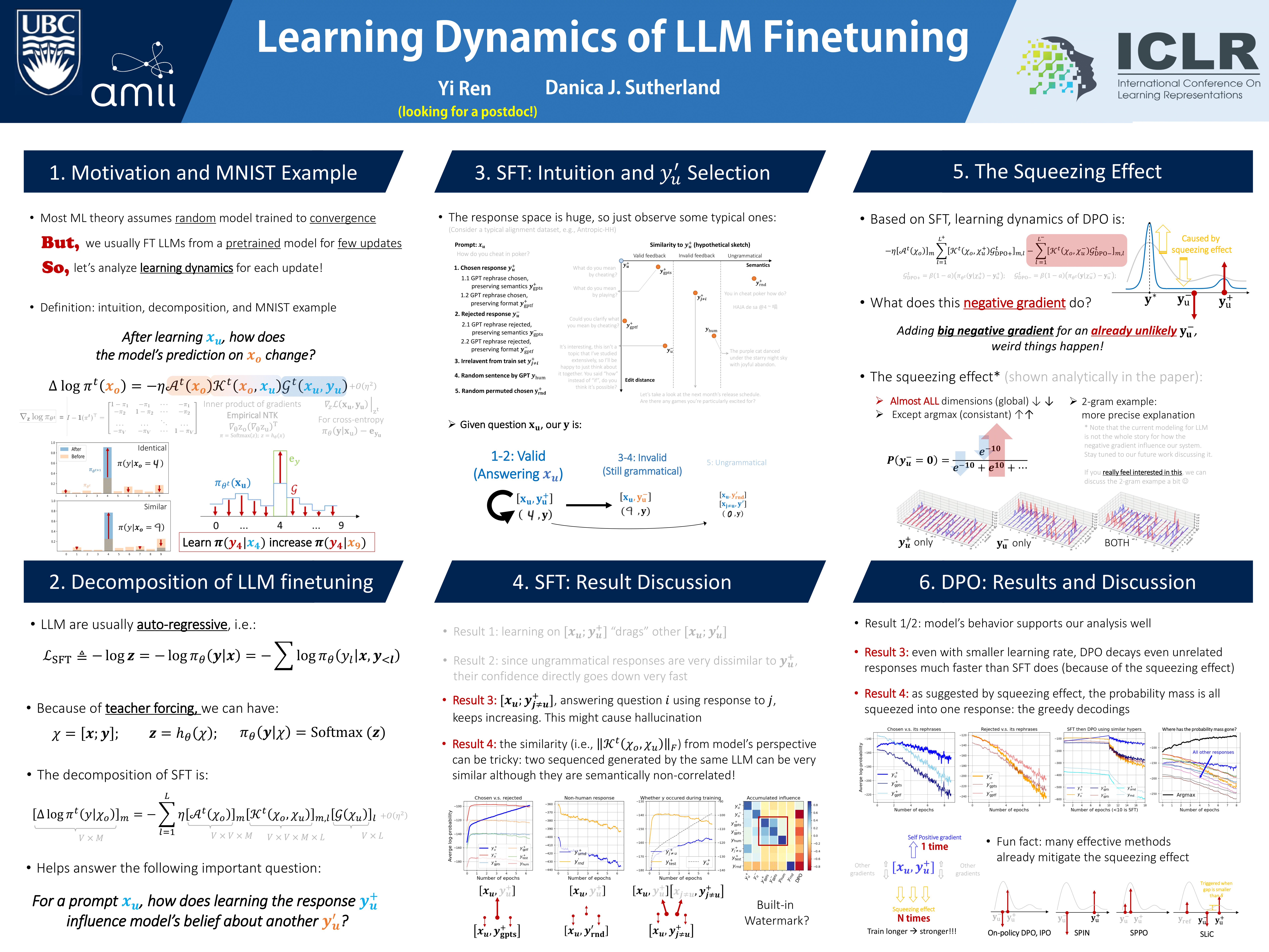
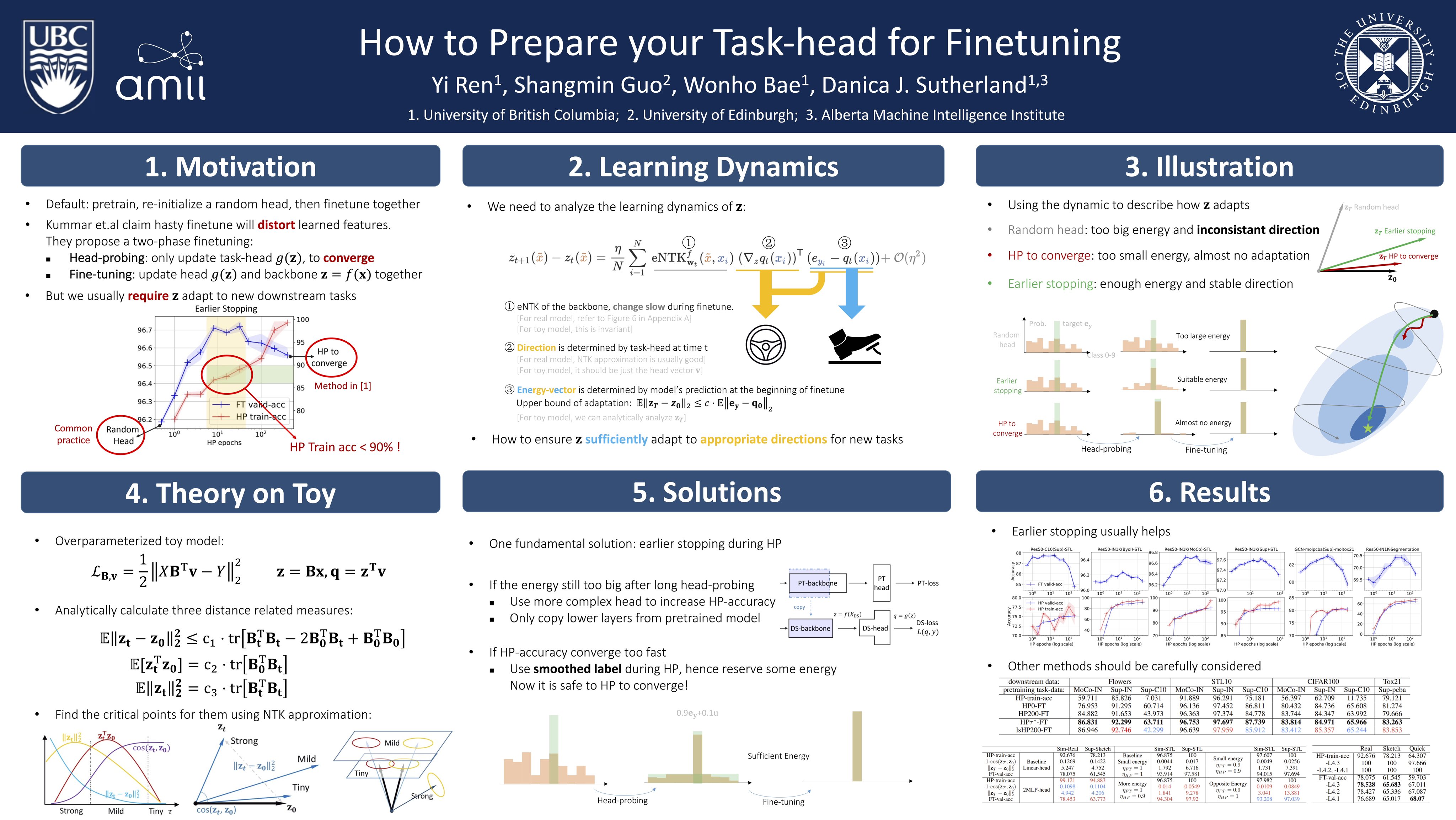
We have also applied learning dynamics to explain various intriguing behaviors in deep learning, such as identifying better supervisory signals (Ren et al., ICLR 2022),
designing fine-tuning heads (Ren et al., ICLR 2023), and fine-tuning large language models (Ren et al., ICLR 2025).
Interestingly, we found that self-preference amplification and simplicity bias are pervasive in gradient descent-based learning systems (Ren et al., CompLearn@NeurIPS 2024).
In addition to this microcosmic inspection of the learning process, I have recently realized that compression theory and Kolmogorov complexity-related theories offer a more macroscopic perspective on simplicity bias.
I believe the mechanisms underlying these concepts -- such as Occam's Razor, the Platonic Representation Hypothesis ,
learning speed advantage, and systematic generalization -- may reflect fundamental principles of learning theory.
I am eager to further explore this fascinating direction and uncover deeper insights.
Intro. of My Research (Recent)
Lifelong (continual) learning enables AI systems to adapt and improve as new knowledge becomes available. Because learning inevitably interacts with a model’s existing knowledge, achieving this goal requires a principled understanding of diverse forms of forgetting, including catastrophic forgetting, intentional unlearning, and time-dependent forgetting. Recently, we have aimed to uncover the underlying mechanisms of these phenomena across different learning algorithms by developing a unified analytical framework, ultimately enabling safer, more efficient, and more capable AI systems.
News
Talks
Publications
Ph.D. Thesis:
- Learning Dynamics of Deep Learning--Force Analysis of Deep Neural Networks
Yi Ren, Supervised by Danica J. Sutherland
University of British Columbia | pdf | slides
Preprints:
- SimKO: Simple Pass@ K Policy Optimization
Ruotian Peng, Yi Ren, Zhouliang Yu, Weiyang Liu, Yandong Wen
arXiv preprint 2025 | pdf | code | page
Journal and Low-Acceptance-Rate Conference Papers:
- On Group Relative Policy Optimization Collapse in Agent Search: The Lazy Likelihood-Displacement
Wenlong Deng, Yushu Li, Boying Gong, Yi Ren, Boying Gong, Christos Thrampoulidis, Xiaoxiao Li
ICML 2026 | pdf - Token Hidden Reward: Steering Exploration-Exploitation in Group Relative Deep Reinforcement Learning
Wenlong Deng, Yi Ren, Yushu Li, Boying Gong, Danica J. Sutherland, Xiaoxiao Li, Christos Thrampoulidis
ICLR 2026 | pdf - On the Effect of Negative Gradient in Group Relative Deep Reinforcement Optimization
Wenlong Deng, Yi Ren, Muchen Li, Danica J Sutherland, Xiaoxiao Li, Christos Thrampoulidis, Danica J. Sutherland
NeurIPS 2025 | pdf - Learning Dynamics of LLM Finetuning
Yi Ren, Danica J. Sutherland
ICLR 2025 (Oral, Outstanding Paper Award, 3 out of 11672 submissions) | pdf | code | poster slides - Bias Amplification in Language Model Evolution: An Iterated Learning Perspective
Yi Ren, Shangmin Guo, Linlu Qiu, Bailin Wang, Danica J. Sutherland
NeurIPS 2024 | pdf | code | poster - AdaFlood: Adaptive Flood Regularization
Wonho Bae, Yi Ren, Mohamad Osama Ahmed, Frederick Tung, Danica J Sutherland, Gabriel L Oliveira
Transactions on Machine Learning Research (TMLR) 2024 | pdf - lpNTK: Better Generalisation with Less Data via Sample Interaction During Learning
Shangmin Guo, Yi Ren, Stefano V. Albrecht, Kenny Smith
ICLR 2024 | pdf - Improving Compositional Generalization using Iterated Learning and Simplicial Embeddings
Yi Ren, Samuel Lavoie, Mikhail Galkin, Danica J. Sutherland, Aaron Courville
NeurIPS 2023 | pdf | code | poster - How to prepare your task head for finetuning
Yi Ren, Shangmin Guo, Wonho Bae, Danica J. Sutherland
ICLR 2023 | pdf | code | poster - Better Supervisory Signals by Observing Learning Paths
Yi Ren, Shangmin Guo, Danica J. Sutherland
ICLR 2022 | pdf | code | poster - Expressivity of Emergent Language is a Trade-Off between Contextual Complexity and Unpredictability
Shangmin Guo, Yi Ren, Kory Mathewson, Simon Kirby, Stefano V. Albrecht, Kenny Smith
ICLR 2022 | pdf | code | workshop-version - Compositional languages emerge in a neural iterated learning model
Yi Ren, Shangmin Guo, Matthieu Labeau, Shay B. Cohen, Simon Kirby
ICLR 2020 | pdf | code | workshop-version
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Workshop Presentations:
- Token Hidden Reward: Steering Exploration-Exploitation in GRPO Training
Wenlong Deng, Yi Ren, Danica J. Sutherland, Xiaoxiao Li, Christos Thrampoulidis,
AI for Math@ICML 2025 (Oral, Best Paper Award) - On the Effect of Negative Gradient in Group Relative Deep Reinforcement Optimization
Wenlong Deng, Yi Ren, Muchen Li, Danica J. Sutherland, Xiaoxiao Li, Christos Thrampoulidis
AI for Math@ICML 2025 | pdf - Understanding Simplicity Bias towards Compositional Mappings via Learning Dynamics
Yi Ren, Danica J. Sutherland
Compositional Learning @NeurIPS 2024 | pdf | code | poster - Economics arena for large language models
Shangmin Guo, Haoran Bu, Haochuan Wang, Yi Ren, Dianbo Sui, Yuming Shang, Siting Lu
Language Gamification @NeurIPS 2024 | pdf - The Emergence of Compositional Languages for Numeric Concepts Through Iterated Learning in Neural Agents
Shangmin Guo, Yi Ren, Serhii Havrylov, Stella Frank, Ivan Titov, Kenny Smith
EmeCom @NeurIPS 2019 | pdf
{kind=link}